AI画像生成
テキスト説明から2D画像を生成し、画像から3Dへの入力として最適化します。3Dパイプラインに入る前に、視覚スタイルを正確に制御できます。
要約
-
テキスト説明から2D画像を生成し、画像から3Dへの入力として最適化します。
-
参照画像がなく、コンセプトアートをすばやく生成したい場合に最適です。
-
3D変換向けに最適化された高品質PNGを出力します(明確な被写体、クリーンな背景)。
-
テキストから3Dとの違い: ここではまず2Dを生成し、その後3Dに変換します。これにより、視覚スタイルをより正確に制御できます。
使用する場合
-
コンセプトはあるが参照画像がなく、3Dに変換する前に可視化したい場合。
-
3Dパイプラインに入る前に、2Dの視覚スタイルを細かく制御したい場合。
使用しない場合
-
すでに参照画像がある → 画像から3Dへ直接進んでください
-
1ステップでテキストから3Dの結果が欲しい → テキストから3Dを使用してください
-
ガイド付きのクリエイティブプロセスが欲しい → ブレインストーミングとコンセプト探索には3D Agentを使用してください
ステップバイステップ
-
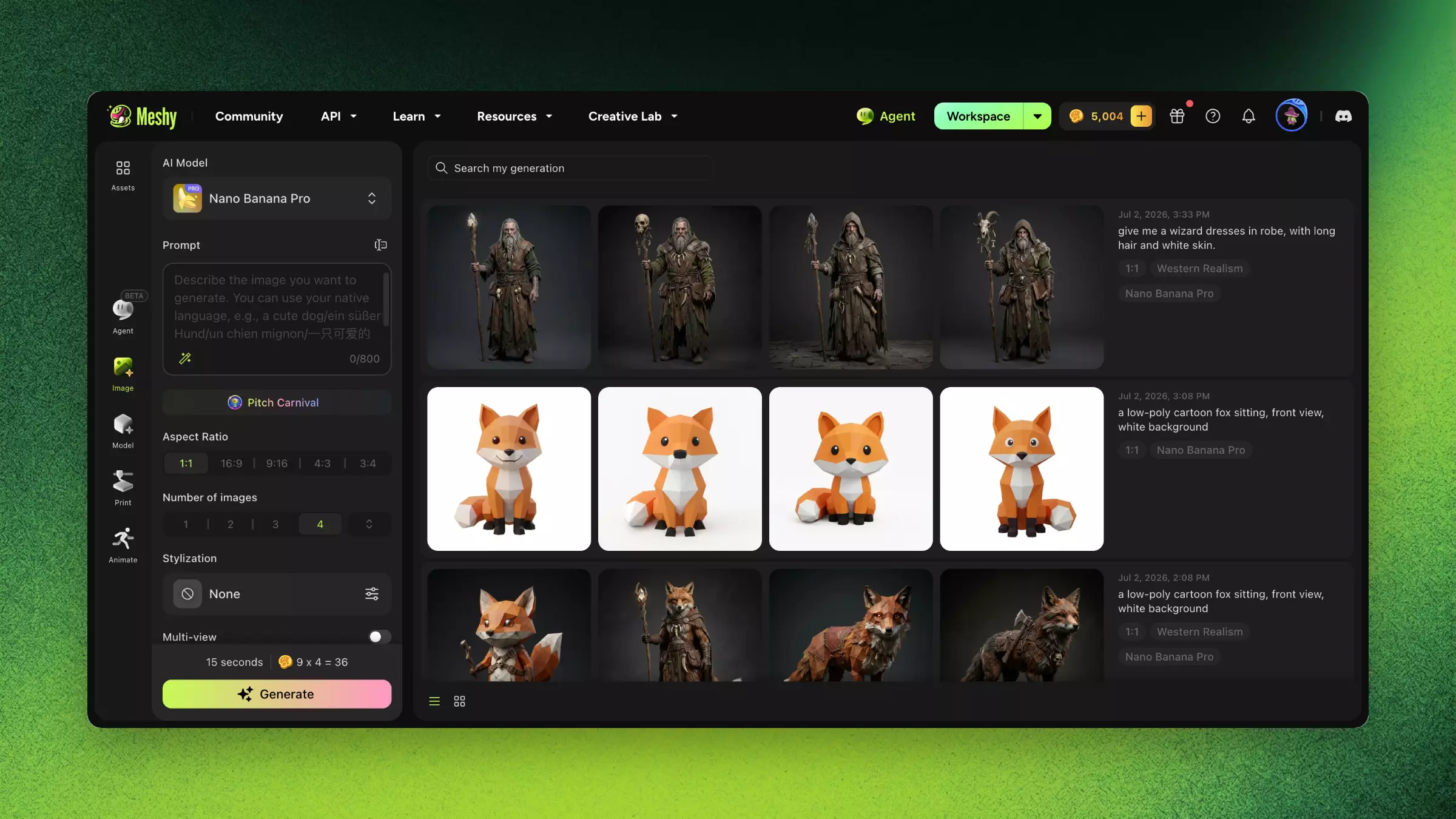
Imageモジュール → AI Image Generationに入ります。
-
説明を入力します(例: "白い背景、正面向きで座っているローポリのカートゥーン風キツネ")。
-
スタイルプリセットを選択します(例: Realistic、Anime、Chibi)。
-
Generateをクリックして待ちます。
-
複数の候補から最適な結果を選びます。
-
"Send to Image to 3D"をクリックして、3D生成パイプラインに直接入ります。
3Dに最適化された画像のためのプロンプトのコツ
-
最適な3D変換角度のために、"正面ビュー"または"3/4ビュー"を指定します。
-
干渉を減らすために、"白い背景"または"クリーンな背景"を追加します。
-
完全な形状を説明します(頭部だけでなく、オブジェクト全体を説明してください)。
-
過度に複雑なシーンは避けてください。単一の被写体が最良の結果を生みます。
FAQ
- Meshyでテキストから画像を生成するにはどうすればよいですか?
- Imageモジュールを開き、AI Image Generationに移動し、説明を入力してスタイルを選び、生成してから、結果を画像から3Dに送信します。
- AI Image Generationとテキストから3Dの違いは何ですか?
- AI Image Generationは、3Dに変換する前に正確な視覚制御を行うため、まず2D画像を作成します。一方、テキストから3Dはテキストから直接モデルに変換します。
- 3D対応画像のプロンプトはどのように書けばよいですか?
- 正面または3/4ビューを指定し、白い背景を追加し、オブジェクト全体を説明し、単一の被写体にしてください。
- Meshyはどのような画像スタイルを生成できますか?
- プリセットにはRealistic、Anime、Chibiなどが含まれており、3Dへのクリーンな変換に最適化されています。
- 生成した画像を画像から3Dに直接送信できますか?
- はい。Send to Image to 3Dをクリックすると、選択した画像をそのまま3Dパイプラインに移動できます。